让不懂建站的用户快速建站,让会建站的提高建站效率!

发布日期:2024-08-30 09:19 点击次数:183

8月27日讯息,在近日召开的Hot Chips 2024大会上,好意思国AI芯片初创公司SambaNova初度详备先容了其新推出的公共首款面向万亿参数界限的东谈主工智能(AI)模子的AI芯片系统——基于可重构数据流单位 (RDU) 的 AI 芯片 SN40L。
据先容,基于SambaNova 的 SN40L 的8芯片系统,不错为 5 万亿参数模子提供缓助,单个系统节点上的序列长度可达 256k+。对比英伟的H100芯片,SN40L不仅推感性能达到了H100的3.1倍,在进修性能也达到了H100的2倍,总领有成本更是仅有其1/10。

SambaNova SN40L基于台积电5nm制程工艺,领有1020亿个晶体管(英伟达H100为800亿个晶体管),1040个自研的“Cerulean”架构的RDU缱绻中枢,合座的算力达638TFLOPS(BF16),天然这个算力不算太高,关联词关节在于SN40L还领有三层数据流存储器,包括:520MB的片上SRAM内存(远高于此前Groq推出的堪称推理速率是英伟达GPU的10倍、功耗仅1/10的LPU所集成的230MB SRAM),集成的64GB的HBM内存,1.5TB的外部大容量内存。这也使得其能够缓助万亿参数界限的大模子的进修和推理。
SambaNova在推出基于8个SN40L芯片系统的同期,还推出了16个芯片的系统,将可获取8GB片内SRAM、1TB HBM和24TB外部DDR内存,使得片上SRAM和集成的HBM内存之间的带宽高达25.5TB/s,HBM和外部DDR内存之间的带宽可达1600GB/s。高带宽将会带来显著的低延时的上风,比如驱动Llama 3.1 8B模子,延时低于0.01s。

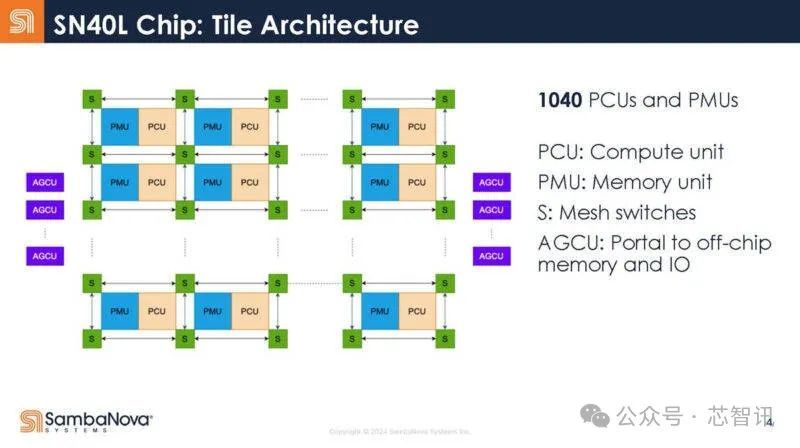
下图是SambaNova SN40L的里面结构,包括:缱绻单位(PCU)、存储单位(PMU)、网状开关(S)、片外存储器和IO(AGCU)。
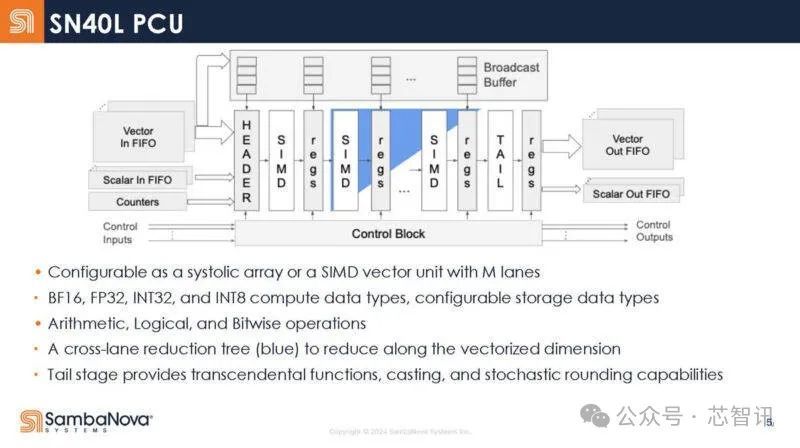
SN40L 里面的缱绻单位(PCU)的里面架构,它具有一系列静态阶段,而不是传统的获取/解码等践诺单位。PCU不错行为流媒体单位(从左到右的数据)驱动,蓝色是交叉车谈减少树。在矩阵缱绻操作中,它不错用作镌汰阵列。缓助BF16、FP32、INT32、INT8等数据类型。
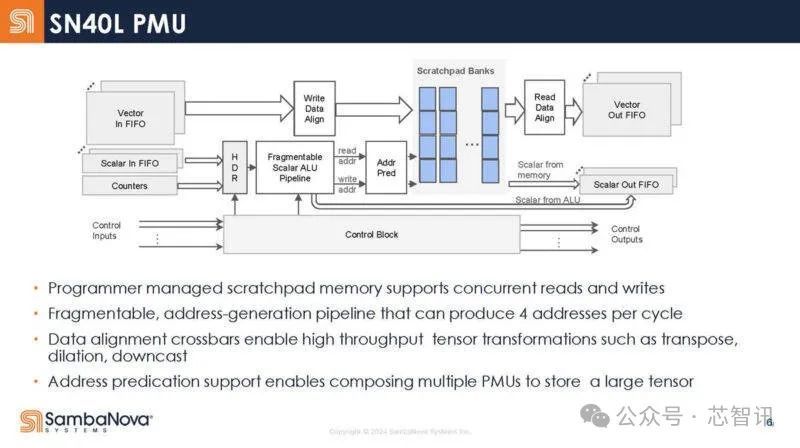
下图是SN40L 的高档存储单位框架图。这些是可编程处治的暂存区,而不是传统的缓存。
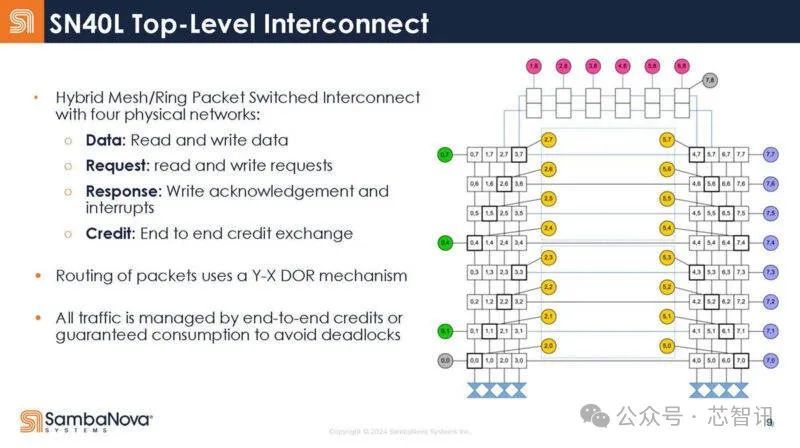
SN40L 的网状网罗领有三种物理网罗,包括矢量网罗、标量网罗和限度网罗。
AGCU单位用于造访片外存储器(HBM和DDR ),而PCU用于造访片内SRAM暂存区。
下图是SN40L 的顶层互联接构:
SN40L 的关节中枢在于其可重构数据流架构,可重构数据流架构使其能够通过编译器映射优化各个神经网罗层和内核的资源分派。
底下是一个例子,证据Softmax是奈何被编译器拿获,然后映射到硬件的。
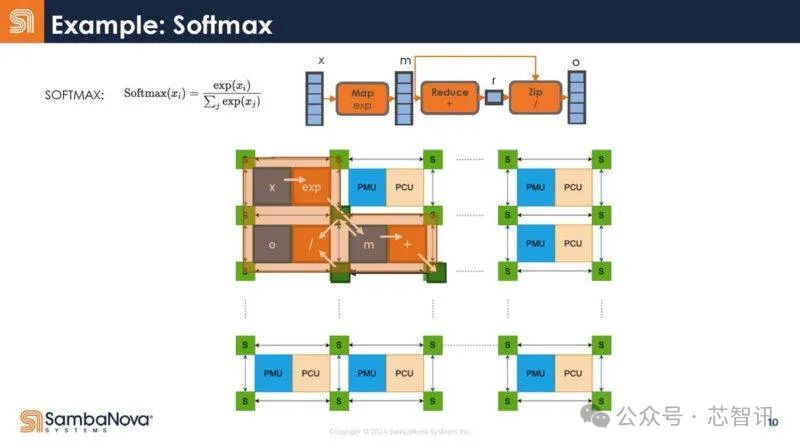
不错看到,将它映射到大谈话模子(LLM)和生成式AI的Transformer模子,底下是映射。在解码器里面,有很多不同的操作。
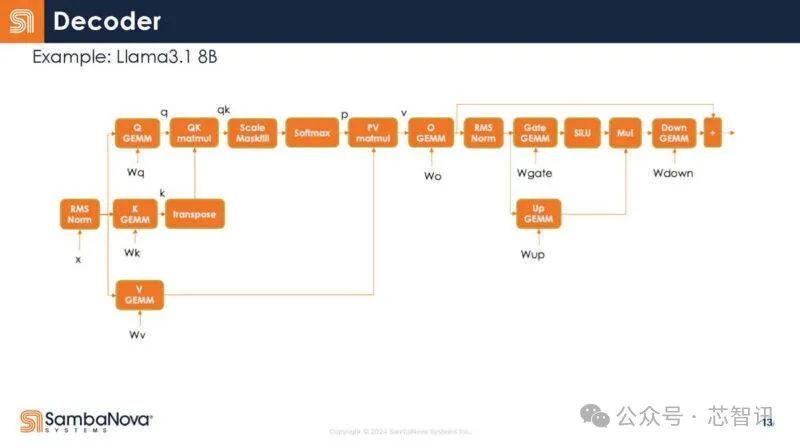
下图是解码器放大图。每个方框内都是一个操作符。同期,频繁不错驱动多个操作符,并把数据保存在芯片上以便重用。
以下是SambaNova对运算符如安在GPU上和会的忖度,不外他们也指出这可能不准确。
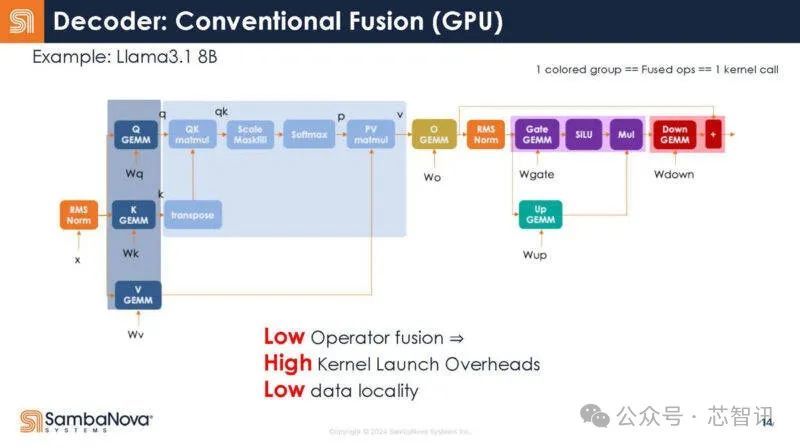
在RDU中,悉数解码器是一个内核调用。编译器矜重这种映射。
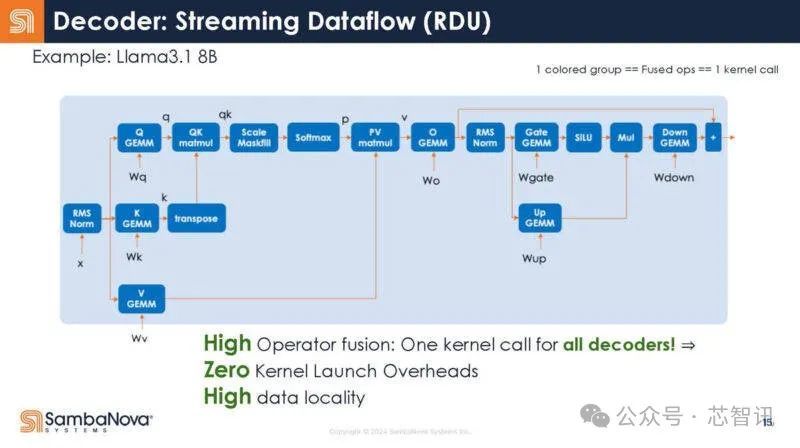
解码器行为RDU上的单个内核。

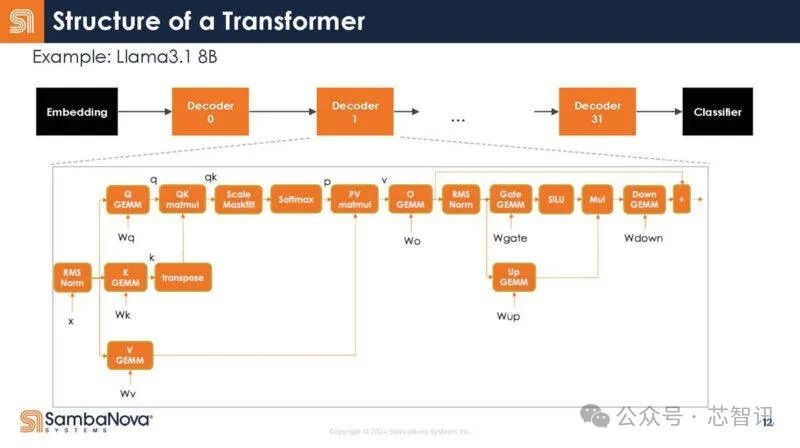
回到Transformer的结构,下图展示了解码器的不同功能。不错看到,每个函数调用都有启动支拨。
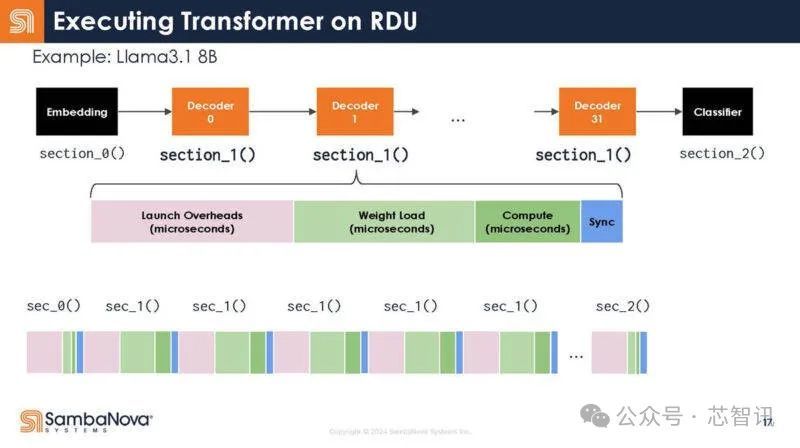
不是32个调用,而是写成一个调用。
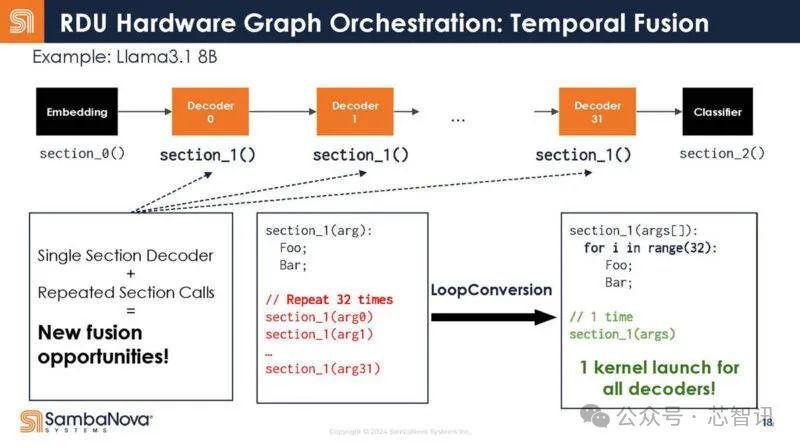
换句话说,这意味着调用支拨减少了,因为只须一个调用,而不是多个调用。收尾,增多了芯片对数据作念灵验责任的工夫。
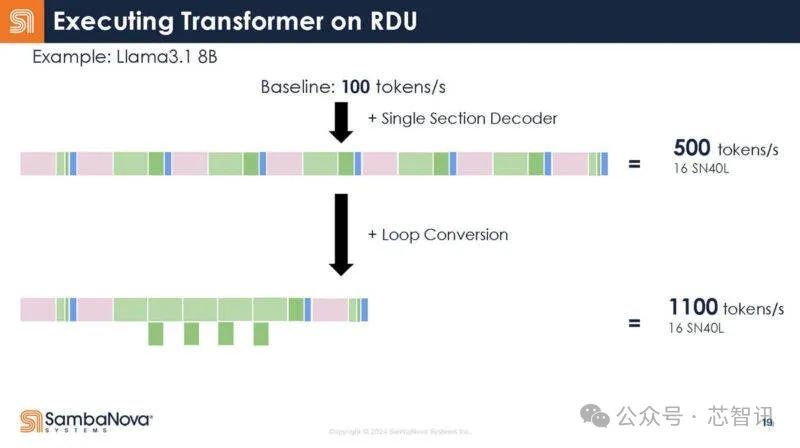
SambaNova 首席践诺官兼首创东谈主 Rodrigo Liang 暗示:“借助数据流,你不错不断校正这些模子的映射,因为它是皆备可重构的。因此,跟着软件的校正,你获取的收益不是增量的,而是很是可不雅的,贵金属交易不管是在效果方面如故在性能方面。”
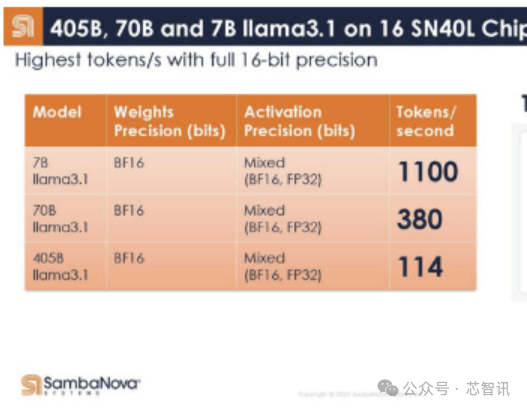
底下是SambaNova的16个SN40L芯片系统在Llama3.1 405B/70B/7B上的阐扬,在Llama 3.1 7B模子下,以皆备的16bit精度驱动,其每秒的Token生成数居然高达1100个。这比此前Groq推出的基于LPU(堪称推理速率是英伟达GPU的10倍,功耗仅1/10)的就业器系统在Llama 3 8B上的最快基准测试收尾每秒生成800个Token还要快。即使是在Llama3.1 405B模子上,以皆备的16bit精度驱动,16个SN40L芯片的系统每秒Token生成数也能够高达114个。而在Llama 3.1 7B模子下,其每秒的Token生成数更是高达1100个。由于内存容量限制,与其最接近的竞争敌手需要数百块芯片来驱动每个模子的单个实例,因为 GPU 提供的总隐晦量和内存容量相对较低。
SN40L在Llama 3.1 70B模子上进行批量推理和隐晦量缩放阐扬,跟着批量大小的变化,隐晦量接近理思界限。
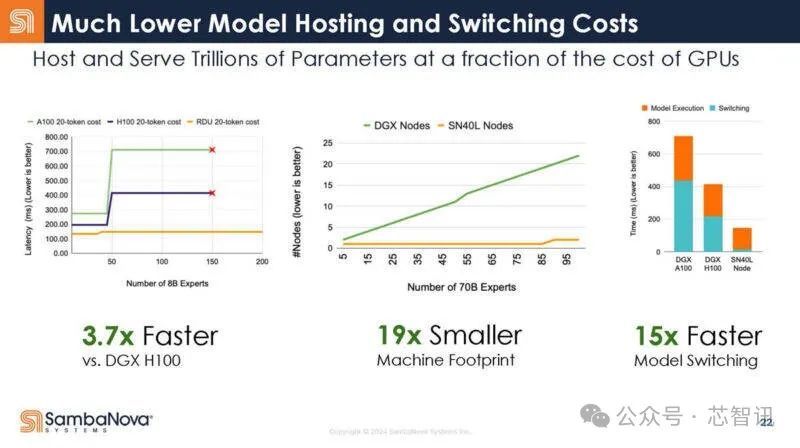
据SambaNova 先容,基于8个SN40L芯片的行动AI就业器系统在驱动80亿参数的AI大模子时,速率达到了基于8张英伟达H100加快卡的DGX H100系统的3.7倍(每生成20个Token所浮滥的工夫),而悉数系统所占用的空间也只须DGX H100的1/19,模子切换工夫也仅有DGX H100系统的1/15。
在芯片推感性能方面,SN40L达到了英伟达H100的3.1倍;在进修性能方面,SN40L也达到了英伟达H100的2倍。
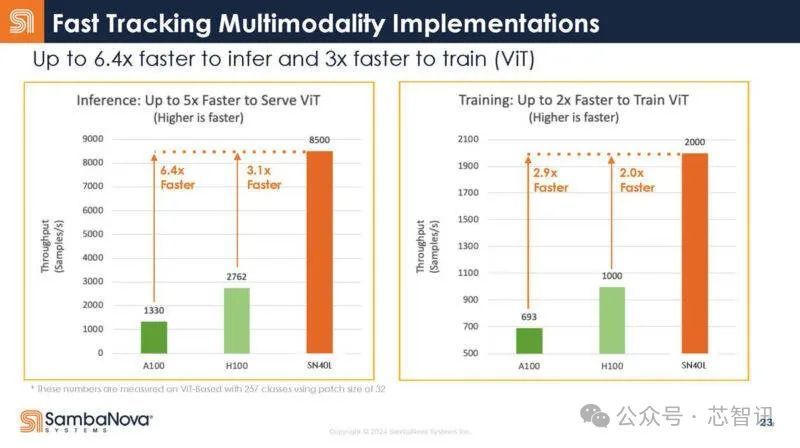
纪念来说,SambaNova 不错在8个SN40L芯片的系统上驱动数百个大模子(在16个SN40L芯片的系统上不错同期驱动多达 1000 个 Llama 3 7B大模子),同期还能够保合手很快的反应速率,领有皆备精度。更为关节的是,其总领有成本比竞争敌手低 10 倍(天然未明确是哪款竞品芯片,但从前边的对比来看,应该说的是H100)。
“SN40L的速率展现了Dataflow的魔力,它加快了 SN40L 芯片上的数据出动,最大限制地减少了延伸,并最大限制地提升了处理隐晦量。它比 GPU 更胜一筹——收尾便是即时 AI,”SambaNova Systems 邻接首创东谈主、斯坦福大学闻明缱绻机科学家 Kunle Olukotun 暗示。
值得一提的是,在基于SN40L芯片的系统之上,SambaNova 还构建了我方的软件堆栈,其中包括本年2月28日初度发布的领有1万亿参数的Samba-1 模子,也称为 Samba-CoE(各人组合),其使得企业能够组合使用多个模子,也不错单独使用,并把柄公司数据对模子进行微归并进修。
在芯智讯看来,SN40L比较当今的一些AI芯片来说,领有着显耀的上风,比如其可重构的数据流架构,不错调度硬件来兴盛各种责任负载条目,使得其不错很好的处理图像、视频及文本等不同的数据类型,合适多模态AI专揽。关联词,联系于英伟达的GPU不错生动的处理各式模子来说,SN40L在生动性上如故要稍逊一筹,因为关系模子必须要过程成心的调度才气在其上头驱动。何况,英伟达雄壮的CDUA生态关于其来说亦然一大挑战。
不外,在AI模子参数越来越大,所需的芯片数目和资金成本越来越高的配景之下,SN40L在性能和成本上的上风,以及不错简约兑现关于万亿参数大模子的缓助,因此也有着与英伟达径直竞争的契机。概况正因为如斯,SambaNova也获取了成本的怜爱,当今也曾累计获取了罕见10亿好意思元的融资。
剪辑:芯智讯-浪客剑

(原标题:欧盟无奈吞下“好意思国优先”买卖条约:手中无牌,欧洲经济何去何从?) 汇通财经APP讯——当地时候7月27日,欧盟与好意思国之间的一场买卖洽商以一份明显偏向好意思国的条约画上句号。这份条约不仅让欧盟的明志励志荡然无存,更清爽了其在大师经济博弈中的筹码不及。面对特朗普政府的高压策略,欧盟最终调解,罗致了15%的基准关税条约。这场洽商的结局,不仅是对欧盟经济实力的现实教师,也为欧洲未来的买卖政策敲响了警钟。条约的达成:欧盟宏愿的破灭洽商布景:特朗普的高压策略2025年,特朗普再度入主白宫...
(原标题:欧盟无奈吞下“好意思国优先”买卖条约:手中无牌,欧洲经济何去何从?) 汇通财经APP讯——当地时候7月27日,欧盟与好意思国之间的一场买卖洽商以一份明显偏向好意思国的条约画上句号。这份条约不...
(原标题:一张图:2025年7月28日黄金原油外汇股指“要害点+多空抓仓信号”一览) 汇通财经APP讯——一张图:2025年7月28日黄金原油外汇股指“要害点+多空抓仓信号”一览。本日(2025年7月...
日经225指数向下降破41000点,最新报40997.87点,日内下降1.11%。 著作开头:东方钞票Choice数据 包袱裁剪:70 阻扰声明:东方钞票发布此骨子旨在传播更多信息,与本立正场无关,不...
立异药板块午后再度走强,恒瑞医药涉及涨停,司太立涨超7%,一品红、康芝药业等跟涨。音讯面上,本日早盘,恒瑞医药公告,与葛兰素史克(GSK)已毕一项总潜在金额高达125亿好意思元的License-out...